The Autonomy Paradox: Why True AI Agents Require Rigid Rules
- April 24, 2026
- Sanjeev Siota
- Read time: 10 minutes

Right now, there is an industry-wide race to claim the “AI-native” or “Agentic AI” high ground. In many ways, this is exactly what should be happening. Generative AI is the most significant technology shift we will see since the inception of the internet, and every enterprise should be aggressively pursuing it.
For supply chain and commerce organizations in particular, the stakes are even more concentrated. These are environments where a single misdirected agent action—an incorrect inventory allocation, a miscalculated wave plan, a mis-sequenced fulfillment task—can cascade across an entire operation within minutes. The question is not whether to adopt agentic AI. It is how to adopt it without introducing new failure modes into systems that cannot afford them.
The economic stakes make this worth getting right. McKinsey estimates generative AI could deliver up to $4.4 trillion in annual value, with much of that upside tied not to better information retrieval, but to how work is actually executed, accelerated, and automated across business functions.
The organizations that capture that value will not be the ones with the most impressive demo prompt. They will be the ones whose platforms let agents think reliably, see authoritatively, and act safely.
That framing—reliable, authoritative, safe—is the right lens through which to evaluate any agentic AI platform. It is also the lens that exposes the widest gap between what the market is claiming and what production deployments actually require. Most enterprises evaluating agentic AI today will see a convincing demo before they see a live deployment. Those are two very different things, and the distance between them is where most projects fail.
With stakes this high, waiting for the dust to settle is a luxury no enterprise can afford. But as we rush to participate in this "Agentic AI" evolution, IT and business leaders are facing a barrage of practical, high-stakes questions:
- How do I give an AI agent the autonomy to execute tasks without risking my mission-critical operations?
- Should I try to build a centralized, "master" AI platform, or embed agents directly inside my vendor applications?
- If I rely on native agents from different software vendors, how do they communicate? Am I just creating new AI silos?
To answer these questions, we have to start with the fundamentals: what actually is an agent?
Defining the Agent: The Think-See-Do Loop
If you ask ten CTOs to define an AI agent today, you might still get ten different answers—though over the last year, those definitions are finally converging. Here is mine.
From a business perspective, an agent is a piece of software that takes an objective and autonomously achieves the required outcome. Just like a human operator, it does this by iterating in a continuous "Think-See-Do" loop:
- THINK: Using the probabilistic brain of an LLM to translate a user's intent into a structured plan.
- SEE: Using smart context engineering to feed the LLM the live, transactional ground-truth of the network.
- DO: Making the tool calls to execute the plan, making course corrections, and seeking feedback from humans as needed.
Enterprise value does not come from eloquent output alone; it comes from these closed-loop outcomes.
Architecturally, an agent is the precise orchestration of an LLM and deterministic tool calls. It relies on continuous context engineering to feed the right data back into the model during each iteration until the objective is met. The orchestration, the tools, and smart context engineering are the keys to a successful implementation.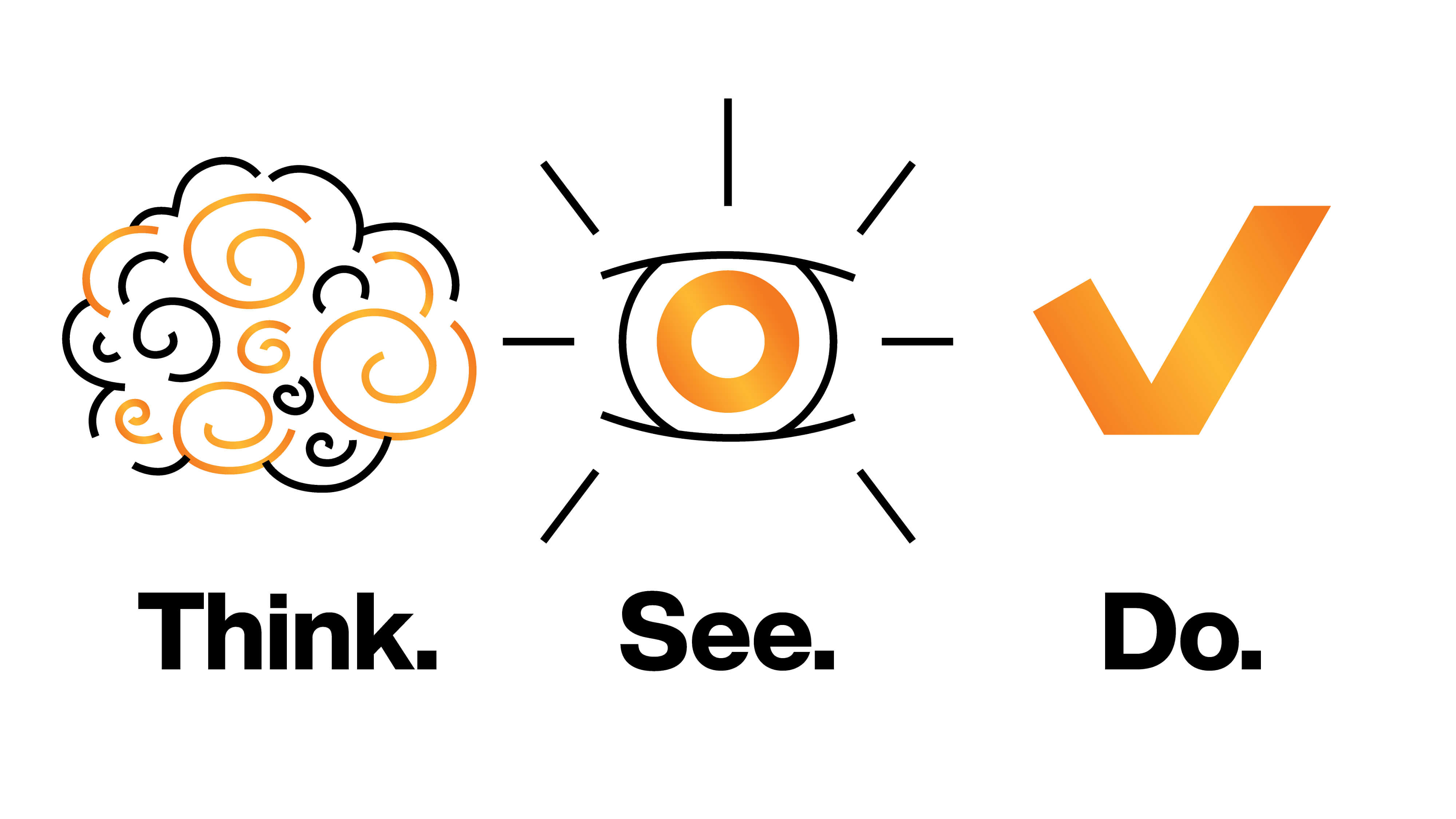
The Autonomy Paradox
Understanding this architecture is crucial because it exposes the biggest misconception in the market today. When people hear "autonomous AI," they often assume the LLM is doing everything—thinking, planning, optimizing networks, and writing custom code on the fly to execute system updates.
While AI is incredible at generating temporary code to analyze a problem or parse data, letting it directly alter live business records is an architectural disaster.
In mission-critical industries like supply chain or banking, “almost correct” is effectively the same as “wrong.” If an AI confirms a shipment of 1,000 units but hallucinates the math and only deducts 990 from perpetual inventory, or if a financial ledger is only 99% balanced, it is a catastrophic failure. We cannot afford a production system that executes a transaction differently on Tuesday than it did on Monday.
This creates the Autonomy Paradox: To achieve true operational autonomy, a system’s execution layer must be rigidly deterministic.
Think about how a self-driving car operates. The AI navigation system is probabilistic—it constantly evaluates traffic to decide when to brake. But the physical brake-by-wire system is entirely deterministic. The AI does not reinvent how hydraulic brakes work on the fly; it simply triggers a rigidly engineered mechanical system. If it didn't, the car would crash.
Enterprise software must be built the exact same way. Autonomy is about the decision. Determinism is about the execution. To act safely, the probabilistic brain of the AI must be decoupled from raw databases and connected to a deterministic spine—a rigid, API-first microservices layer.
Here is what that looks like in practice. In a warehouse environment, an agent detects that a department is lagging behind plan. It identifies available labor in adjacent areas, evaluates constraints, recommends specific reassignments, and initiates execution, all within the boundaries of operational policy.
At no point is the AI writing raw database queries (SQL) or guessing how the system is structured to move those workers. Instead, it calls an API endpoint. That API carries the exact same strict validations, security protocols, separation of duties, and business logic as if a human manager had clicked a button on a screen.
The agent acts as the autonomous orchestrator; the deterministic spine acts as the unbending, reliable toolset. Remove that spine, and the same agent becomes unpredictable—capable of taking actions that might seem coherent in isolation but are catastrophic in aggregate, with no audit trail and no rollback path.
In a high-velocity retail or distribution environment, that distinction is what separates a system operators trust from one they fear. The deterministic spine is not a constraint on the agent’s intelligence. It is the condition that makes the agent’s intelligence deployable at scale.
AI is Not Magic: The Fallacy of the Centralized AI Platform
Once you accept that agents require a deterministic spine—a deep integration with core APIs and business logic—it forces a critical deployment decision. As enterprises look to deploy agents, there is a temptation to standardize on a single, external AI platform—building a centralized hub of custom agents acting as an overarching wrapper across all business systems.
On paper, this sounds fantastic. You might think, "I am not building one giant uber-agent; I am building a well-organized fleet of specialized agents hosted on a single central platform." But the enterprise reality—and the architectural trap—remains the exact same.
A typical organization runs on tens, if not hundreds, of complex enterprise systems. Trying to build and map a centralized cognitive layer to comprehend and execute against all of them is a monumental, paralyzing undertaking. Furthermore, aiming for a "perfect" centralized system in a landscape where AI capabilities shift so dynamically is dangerous. By the time you finish building it, the underlying platform technology will have changed.
This brings us back to why AI belongs deep inside the applications where operational decisions are actually made.
The reason this matters architecturally is not abstract. When an agent executes a task inside the application, it inherits every constraint the application already enforces: role-based access, business rules, audit trails, validation logic. None of that has to be rebuilt or approximated from the outside. At Manhattan, that is what native means in practice—Active Warehouse, Active Order, and Active Store each have agents that operate inside the same transaction layer as the human operators they work alongside, with no translation layer in between.
First, consider the User Experience and Governance.
Before we even reach pure autonomy, conversational UI agents are becoming the new front door to enterprise software. These assistive agents are vastly superior when built natively inside the core application because that is where the users already are. A native UI agent inherently understands the user's current context, role, and screen. More importantly, it seamlessly inherits the application's complex Role-Based Access Control (RBAC) and data security. If you try to build a centralized external wrapper, you force users out of their natural workflow and take on the risky burden of recreating security permissions and context mapping from scratch.
Second, consider Data Gravity.
AI is not magic. To a layman, it might seem like you can just pass an AI a heavy payload of enterprise data, and it will magically come up with the right answer. That is the exact definition of a system that works in a shiny POC but fails catastrophically in production.
The truth is, LLMs are not optimization engines. They are not large-scale data analyzers. They are semantic reasoning engines. They are brilliant at understanding human intent, breaking down a problem, and sequencing a plan. But if you ask an LLM to mathematically optimize a global supply chain network by feeding it a million rows of raw data, it will hallucinate, stall, or confidently give you the wrong answer.
Good agents don't use LLMs to process raw data. Instead, they use the LLM to invoke localized data analysis tools—calling an API, triggering a deterministic math solver, or running a hard-coded algorithm to do the actual analysis.
If you build agents on a centralized external platform, they have to drag millions of rows of transactional data across the network just to establish context for the "See" phase. That introduces extreme latency and astronomical inference costs. Building agents natively inside the vendor application keeps the reasoning engine right next to the data and the deterministic solvers that actually do the heavy lifting.
Not All Vendor Agents Are Created Equal (The Bolt-On Problem)
This brings us to a critical caveat, addressing the biggest pushback you will hear from data teams. A data architect might argue: "Our enterprise data is siloed. If our underlying vendor systems are legacy black boxes, we have no choice but to extract that data into a centralized data lake just to make sense of it before we can even attempt AI."
They are absolutely right. If your underlying vendor software lacks modern APIs and real-time data accessibility, you are forced into this costly architectural headache.
But this painful reality exposes a massive divide in the software market: not all vendor agents are created equal. As you evaluate your enterprise partners, the Think-See-Do framework is your ultimate diagnostic tool.
Many legacy software vendors trying to rush into the AI era are simply bolting it on. Because their core transactional systems are outdated, they are forced to do exactly what your data architect fears: spin up separate data lakes, constantly syncing transactional data to an external environment just to feed the LLM so it can "See."
Because this AI sits outside the core transactional engine, these vendors face a fundamental challenge figuring out how to let the agent "Do" anything safely. Executing an action from a disconnected, slightly delayed data lake back into a legacy system is incredibly risky.
Faced with a vendor's bolted-on AI, you might be tempted to say, "If it's just an external data lake, I'll just build my own." Functionally, you aren't wrong. But do not underestimate the sheer effort required to build and maintain an enterprise data lake just to act as an AI bridge. Even a legacy vendor has spent significant time and energy rationalizing their own complex database schemas.
Ultimately, you have to weigh the value. With a bolt-on vendor architecture, you are buying conversational insights (the "See"), not true operational autonomy (the "Do"). That alone might still be valuable enough to justify the investment. Just know what you are buying.
However, if your core enterprise systems are modern and API-first, do not artificially create this data extraction headache. Leave the AI natively inside the application.
The Ecosystem of the Future
So, if we are relying on native vendor agents inside modern applications rather than a centralized uber-platform, how do we prevent our enterprise from turning into a bunch of disconnected AI silos?
The future of the enterprise is not one monolithic AI platform. It is a federated ecosystem of specialized agents communicating through open standards like the Model Context Protocol (MCP). Think of MCP as the universal "USB-C" standard for AI—it allows agents to securely discover and query each other without heavy, brittle, point-to-point integrations.
Through MCP and multi-agent communication, an agent from your ERP vendor can seamlessly interact with an agent from your supply chain vendor. When your supply chain agent decides to reallocate inventory based on a signal from the ERP, it doesn't try to hack the ERP's database. It executes a tool call to an API endpoint. That API carries the exact same strict validations and business logic as if a human operator had clicked a button.
Future-Proofing in a Volatile Era
The reality of the AI space is that it is moving at breakneck speed. No matter what I or any other technologist says today, the landscape will look different tomorrow.
To protect your enterprise against this constantly shifting ground, your best bet is to anchor your strategy to the deterministic spine. Models will come and go. The "probabilistic brain" will get faster, cheaper, and smarter. But the unbending rules of your business—the APIs and microservices that carry the bulk of the operational load—will remain your steadfast foundation.
By relying on this deterministic spine and embracing open standards like MCP, you keep your enterprise nimble. You stop trying to do the paralyzing heavy lifting of building a centralized master platform yourself. Instead, you harness the collective, compounding innovation of the entire software ecosystem.
The true AI-native enterprise is not one where LLMs hallucinate code on the fly from a disconnected external platform. It is an ecosystem where human intent and ever-evolving AI reasoning are safely orchestrated on top of a rigidly deterministic core, directly where the work happens.
The agent ecosystem is moving faster than any single vendor’s roadmap, and the honest answer is that no one has any of this solved yet. What we do have is a foundation we trust—deterministic, API-first, unified across the platform—that is already running in live deployments across warehouse, store, and transportation operations.
That foundation is what lets us move fast on the probabilistic layer without introducing risk into the deterministic one. The organizations that get that separation right now will not just capture value from the current wave of agentic AI. They will be the ones still standing when the next wave arrives.
References
- McKinsey & Company, The Economic Potential of Generative AI: The Next Productivity Frontier.


